 #### 1.MaxKB MaxKB = Max Knowledge Base,是一款基于 LLM 大语言模型的开源[知识库](https://so.csdn.net/so/search?q=%E7%9F%A5%E8%AF%86%E5%BA%93&spm=1001.2101.3001.7020)问答系统,旨在成为企业的最强大脑。它能够帮助企业高效地管理知识,并提供智能问答功能。想象一下,你有一个虚拟助手,可以回答各种关于公司内部知识的问题,无论是政策、流程,还是技术文档,MaxKB 都能快速准确地给出答案:比如公司内网如何访问、如何提交视觉设计需求等等 官方网址:https://maxkb.cn/ ##### 1.1 简介 1. `开箱即用`:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化、RAG(检索增强生成),智能问答交互体验好; 2. `无缝嵌入`:支持零编码快速嵌入到第三方业务系统,让已有系统快速拥有智能问答能力,提高用户满意度; 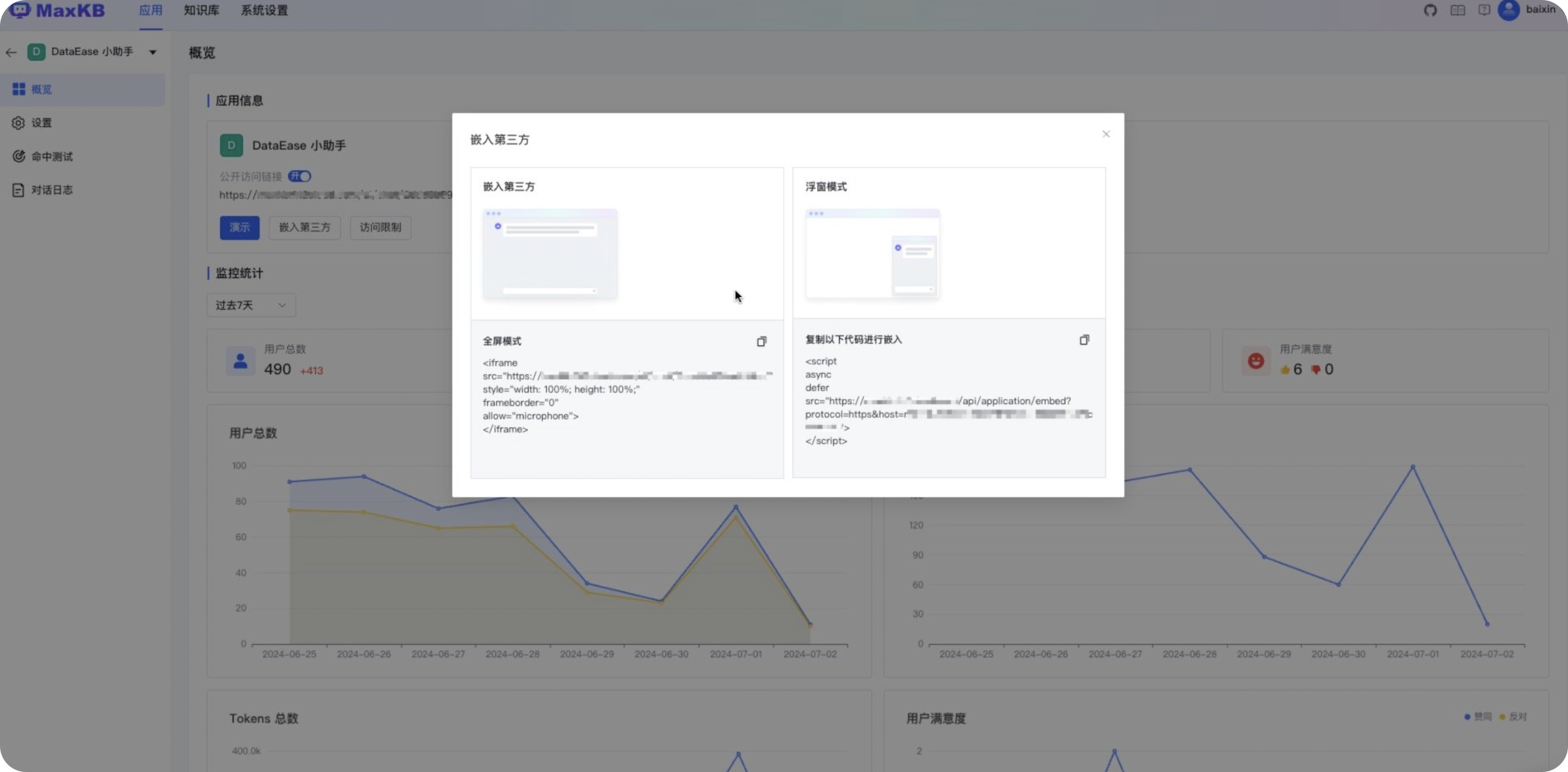 1. `灵活编排`:内置强大的工作流引擎,支持编排 AI 工作流程,满足复杂业务场景下的需求; 2. `模型中立`:支持对接各种大语言模型,包括本地私有大模型(Llama 3 / Qwen 2 等)、国内公共大模型(通义千问 / 智谱 AI / 百度千帆 / Kimi / DeepSeek 等)和国外公共大模型(OpenAI / Azure OpenAI / Gemini 等)。  ##### 技术框架和原理 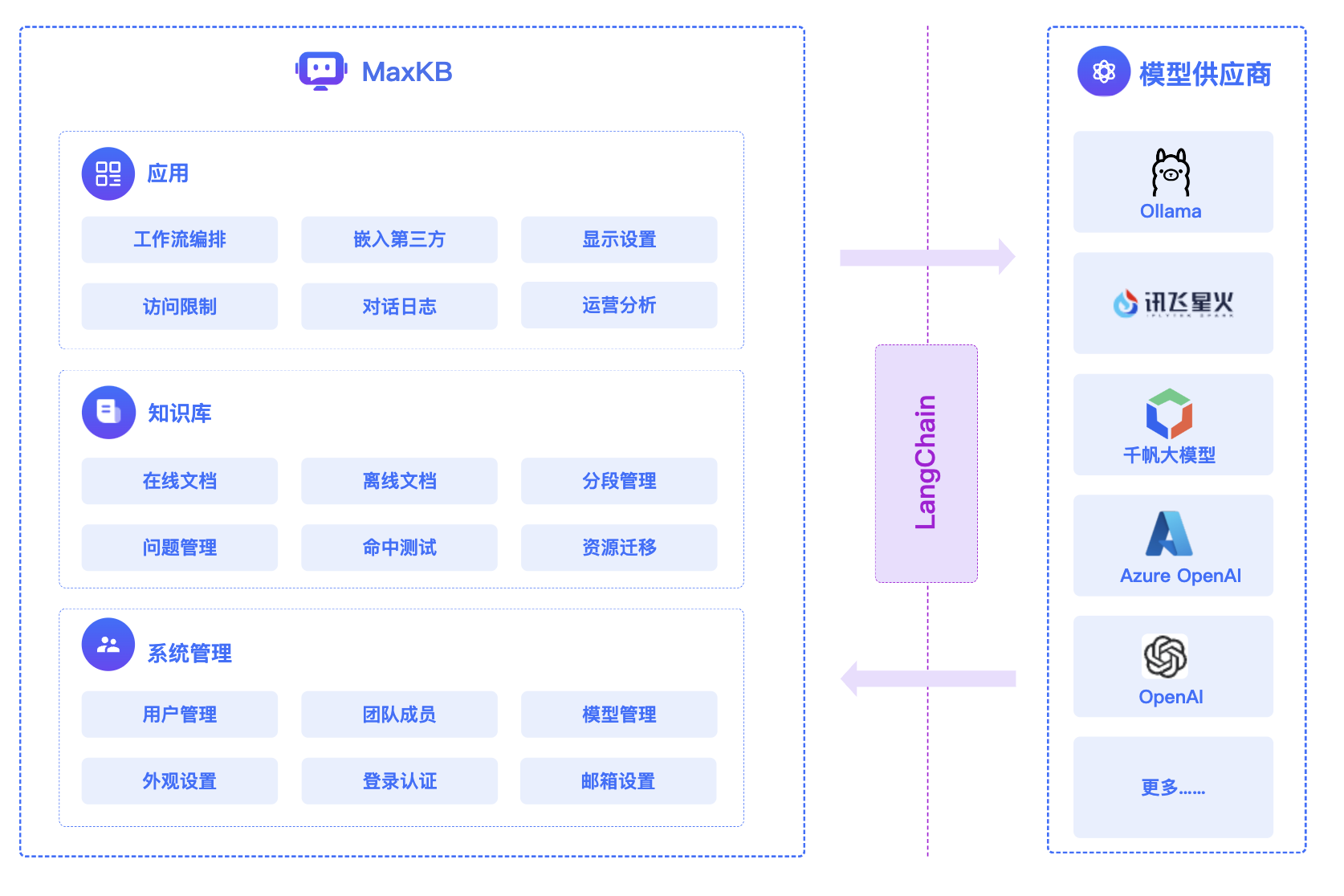 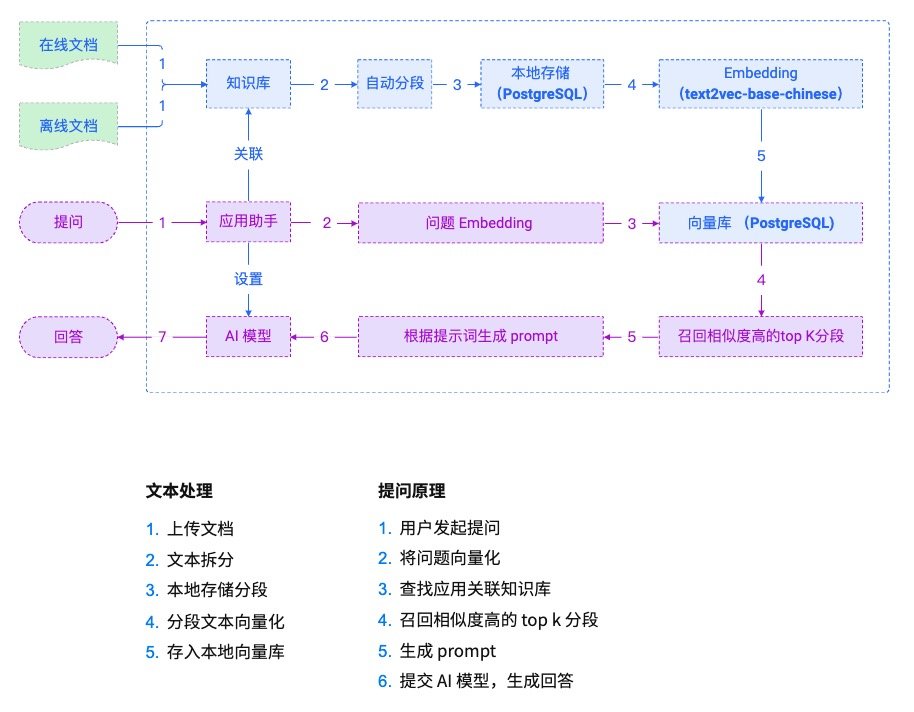 * 技术栈 * 前端:Vue.js、logicflow * 后端:Python / Django * Langchain:Langchain * 向量数据库:PostgreSQL / pgvector * 大模型:Ollama、Azure OpenAI、OpenAI、通义千问、Kimi、百度千帆大模型、讯飞星火、Gemini、DeepSeek等。 #### 2.Dify Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。 由于 Dify 内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的流程编排,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上 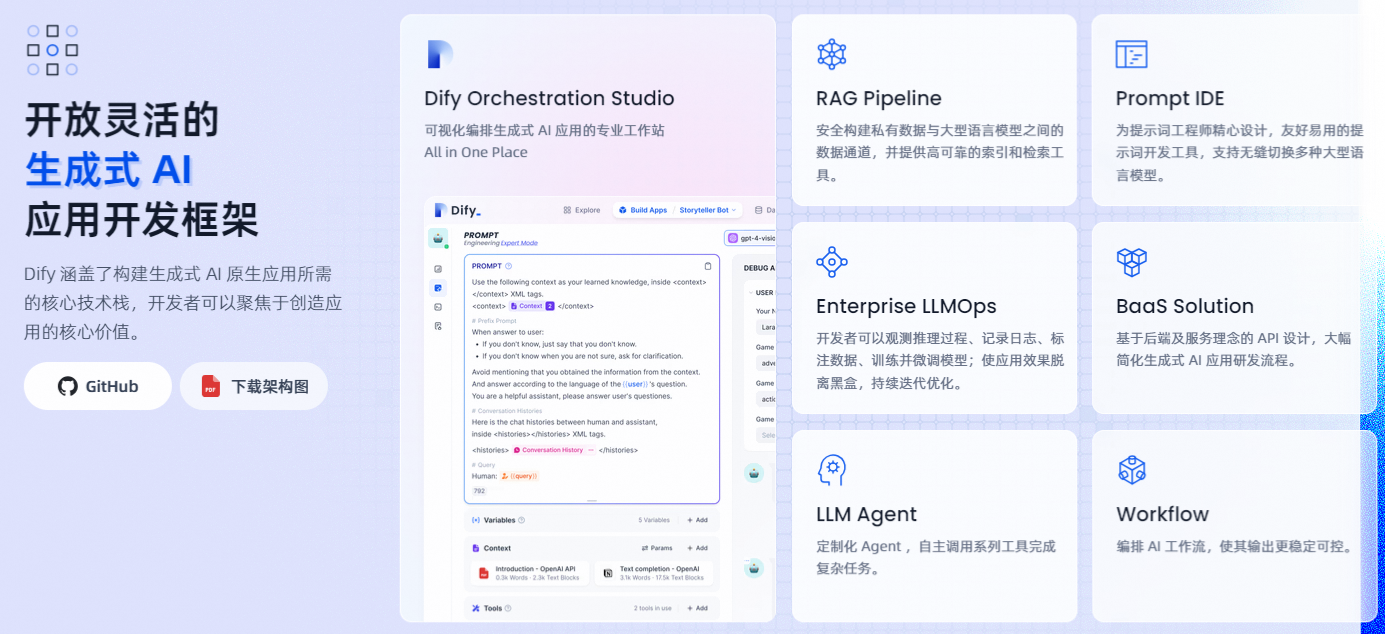 * 官网:https://dify.ai/zh * github:https://github.com/langgenius/dify?tab=readme-ov-file ##### 2.1 简介 Dify 是一个开源的 LLM 应用开发平台。其直观的界面结合了 AI 工作流、RAG 管道、Agent、模型管理、可观测性功能等,让您可以快速从原型到生产。以下是其核心功能列表: 1. `工作流`: 在画布上构建和测试功能强大的 AI 工作流程,利用以下所有功能以及更多功能。 2. `全面的模型支持`: 与数百种专有/开源 LLMs 以及数十种推理提供商和自托管解决方案无缝集成,涵盖 GPT、Mistral、Llama3 以及任何与 OpenAI API 兼容的模型。 3. `Prompt IDE`: 用于制作提示、比较模型性能以及向基于聊天的应用程序添加其他功能(如文本转语音)的直观界面。 4. `RAG Pipeline`: 广泛的 RAG 功能,涵盖从文档摄入到检索的所有内容,支持从 PDF、PPT 和其他常见文档格式中提取文本的开箱即用的支持。 5. `Agent 智能体`: 您可以基于 LLM 函数调用或 ReAct 定义 Agent,并为 Agent 添加预构建或自定义工具。Dify 为 AI Agent 提供了50多种内置工具,如谷歌搜索、DELL·E、Stable Diffusion 和 WolframAlpha 等。 6. `LLMOps`: 随时间监视和分析应用程序日志和性能。您可以根据生产数据和标注持续改进提示、数据集和模型。 7. `后端即服务`: 所有 Dify 的功能都带有相应的 API,因此您可以轻松地将 Dify 集成到自己的业务逻辑中。 ##### 2.2 系统框架 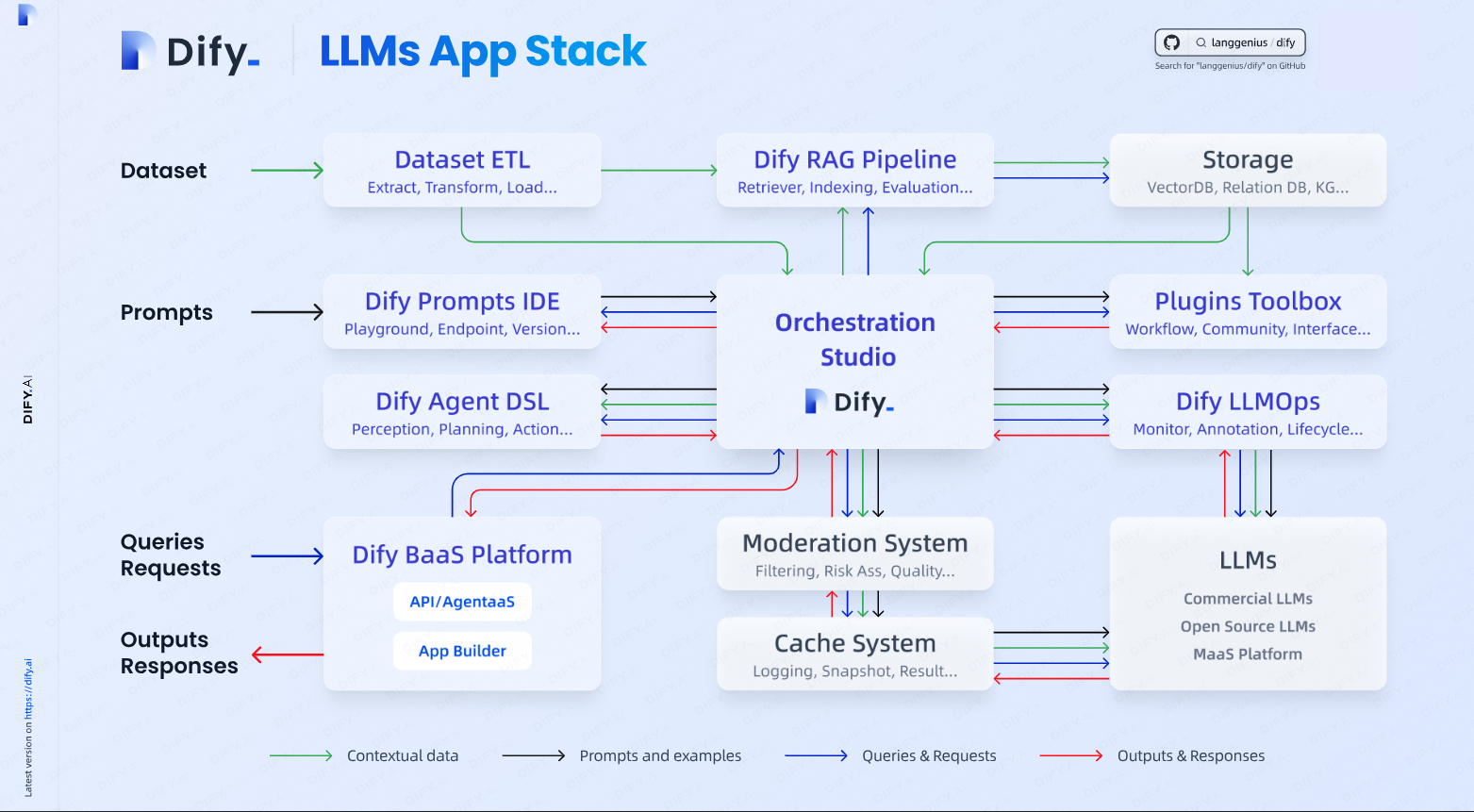 工作流通过将复杂的任务分解成较小的步骤(节点)降低系统复杂度,减少了对提示词技术和模型推理能力的依赖,提高了 LLM 应用面向复杂任务的性能,提升了系统的可解释性、稳定性和容错性。 Dify 工作流分为两种类型: * Chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。 * Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。 为解决自然语言输入中用户意图识别的复杂性,Chatflow 提供了问题理解类节点。相对于 Workflow 增加了 Chatbot 特性的支持,如:对话历史(Memory)、标注回复、Answer 节点等。 为解决自动化和批处理情景中复杂业务逻辑,工作流提供了丰富的逻辑节点,如代码节点、IF/ELSE 节点、模板转换、迭代节点等,除此之外也将提供定时和事件触发的能力,方便构建自动化流程。 * 常见案例 * 客户服务:通过将 LLM 集成到您的客户服务系统中,您可以自动化回答常见问题,减轻支持团队的工作负担。 LLM 可以理解客户查询的上下文和意图,并实时生成有帮助且准确的回答。 * 内容生成:无论您需要创建博客文章、产品描述还是营销材料,LLM 都可以通过生成高质量内容来帮助您。只需提供一个大纲或主题,LLM将利用其广泛的知识库来制作引人入胜、信息丰富且结构良好的内容。 * 任务自动化:可以与各种任务管理系统集成,如 Trello、Slack、Lark、以自动化项目和任务管理。通过使用自然语言处理,LLM 可以理解和解释用户输入,创建任务,更新状态和分配优先级,无需手动干预。 * 数据分析和报告:可以用于分析大型数据集并生成报告或摘要。通过提供相关信息给 LLM,它可以识别趋势、模式和洞察力,将原始数据转化为可操作的智能。对于希望做出数据驱动决策的企业来说,这尤其有价值。 * 邮件自动化处理:LLM 可以用于起草电子邮件、社交媒体更新和其他形式的沟通。通过提供简要的大纲或关键要点,LLM 可以生成一个结构良好、连贯且与上下文相关的信息。这样可以节省大量时间,并确保您的回复清晰和专业。 #### 3.FastGPT FastGPT是一个功能强大的平台,专注于知识库训练和自动化工作流程的编排。它提供了一个简单易用的可视化界面,支持自动数据预处理和基于Flow模块的工作流编排。FastGPT支持创建RAG系统,提供自动化工作流程等功能,使得构建和使用RAG系统变得简单,无需编写复杂代码。 * 官方:https://fastgpt.in/ * github:https://github.com/labring/FastGPT ##### 3.1 FastGPT 能力 1. `专属 AI 客服` :通过导入文档或已有问答对进行训练,让 AI 模型能根据你的文档以交互式对话方式回答问题。 * 多库复用,混用 * chunk 记录修改和删除 * 源文件存储 * 支持手动输入,直接分段,QA 拆分导入 * 支持 txt,md,html,pdf,docx,pptx,csv,xlsx (有需要更多可 PR file loader) * 支持 url 读取、CSV 批量导入 * 混合检索 & 重排 2. `简单易用的可视化界面` :FastGPT 采用直观的可视化界面设计,为各种应用场景提供了丰富实用的功能。通过简洁易懂的操作步骤,可以轻松完成 AI 客服的创建和训练流程。 3. `自动数据预处理`:提供手动输入、直接分段、LLM 自动处理和 CSV 等多种数据导入途径,其中“直接分段”支持通过 PDF、WORD、Markdown 和 CSV 文档内容作为上下文。FastGPT 会自动对文本数据进行预处理、向量化和 QA 分割,节省手动训练时间,提升效能。 4. `工作流编排` :基于 Flow 模块的工作流编排,可以帮助你设计更加复杂的问答流程。例如查询数据库、查询库存、预约实验室等。 * 提供简易模式,无需操作编排 * 工作流编排 * 工具调用 * 插件 - 工作流封装能力 * Code sandbox 5. `强大的 API 集成` :FastGPT 对外的 API 接口对齐了 OpenAI 官方接口,可以直接接入现有的 GPT 应用,也可以轻松集成到企业微信、公众号、飞书等平台。 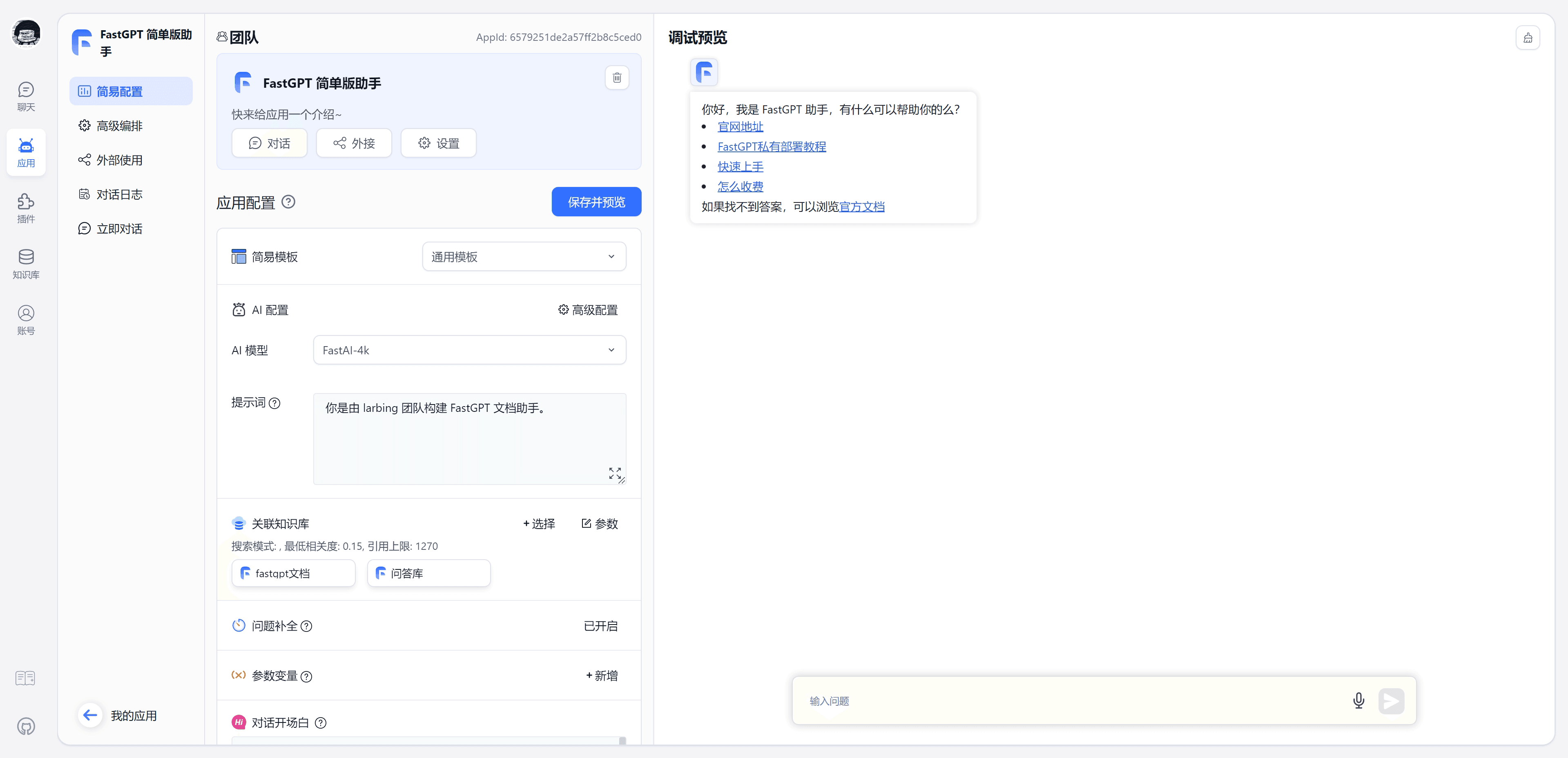 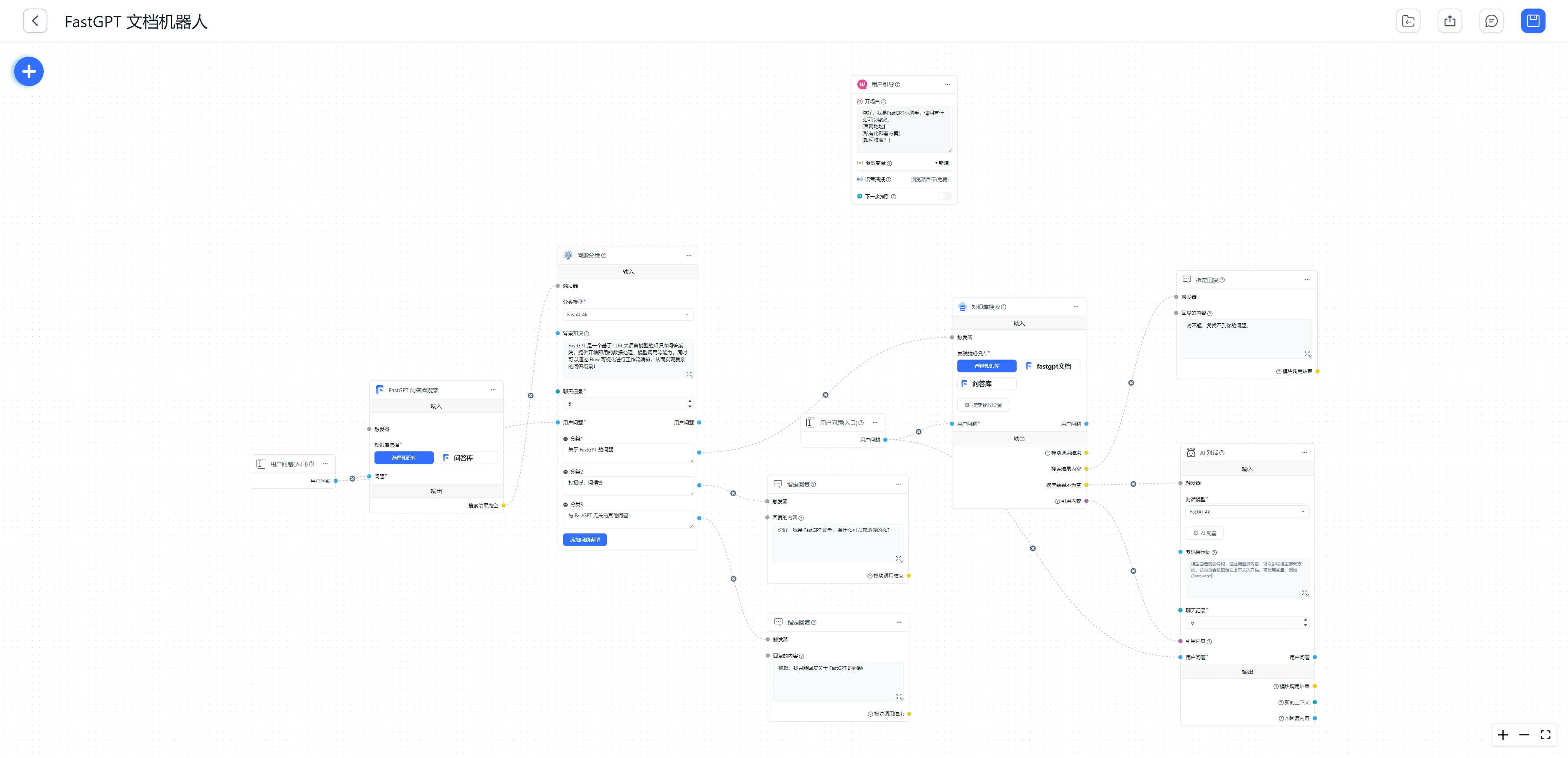 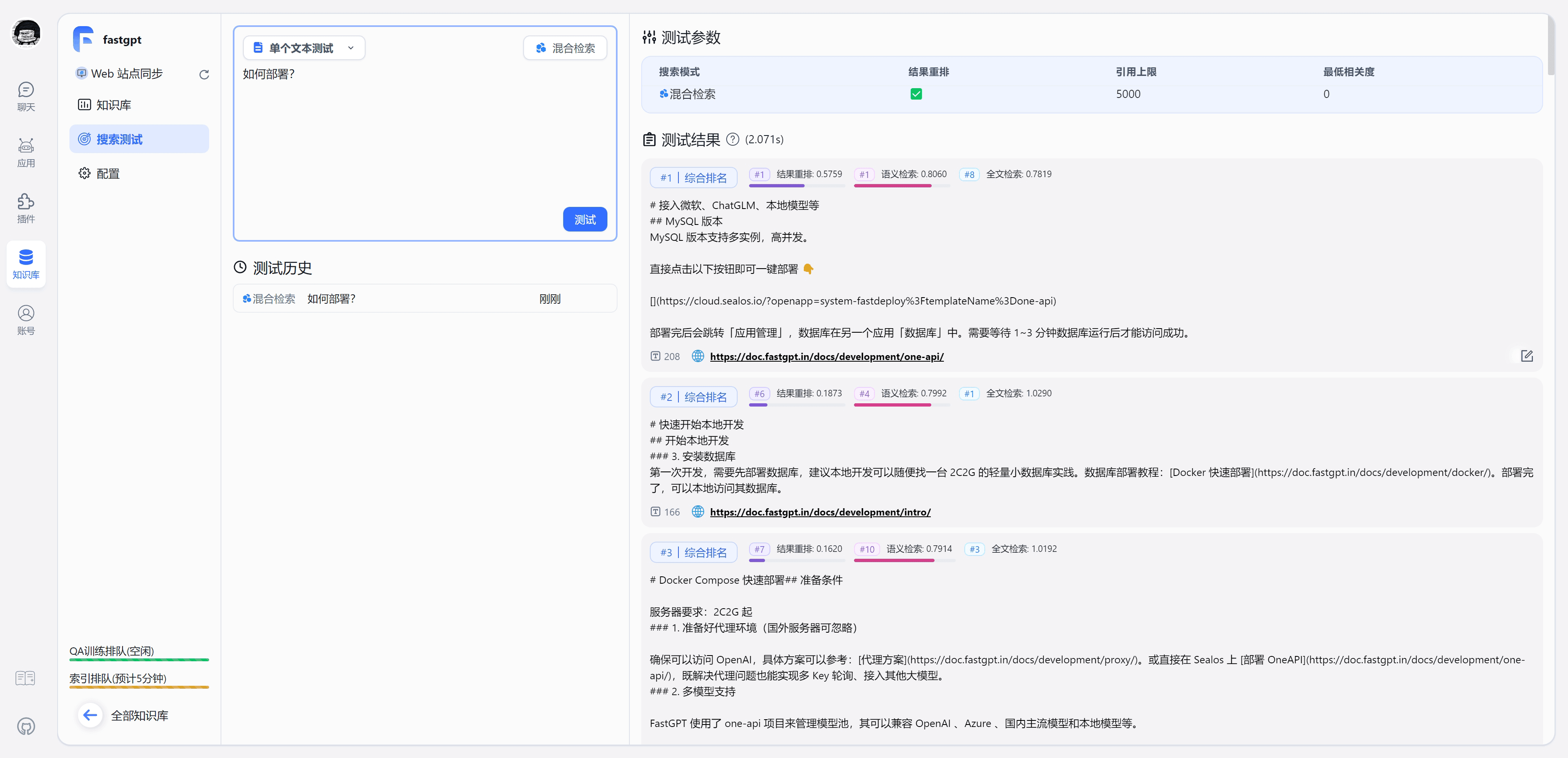 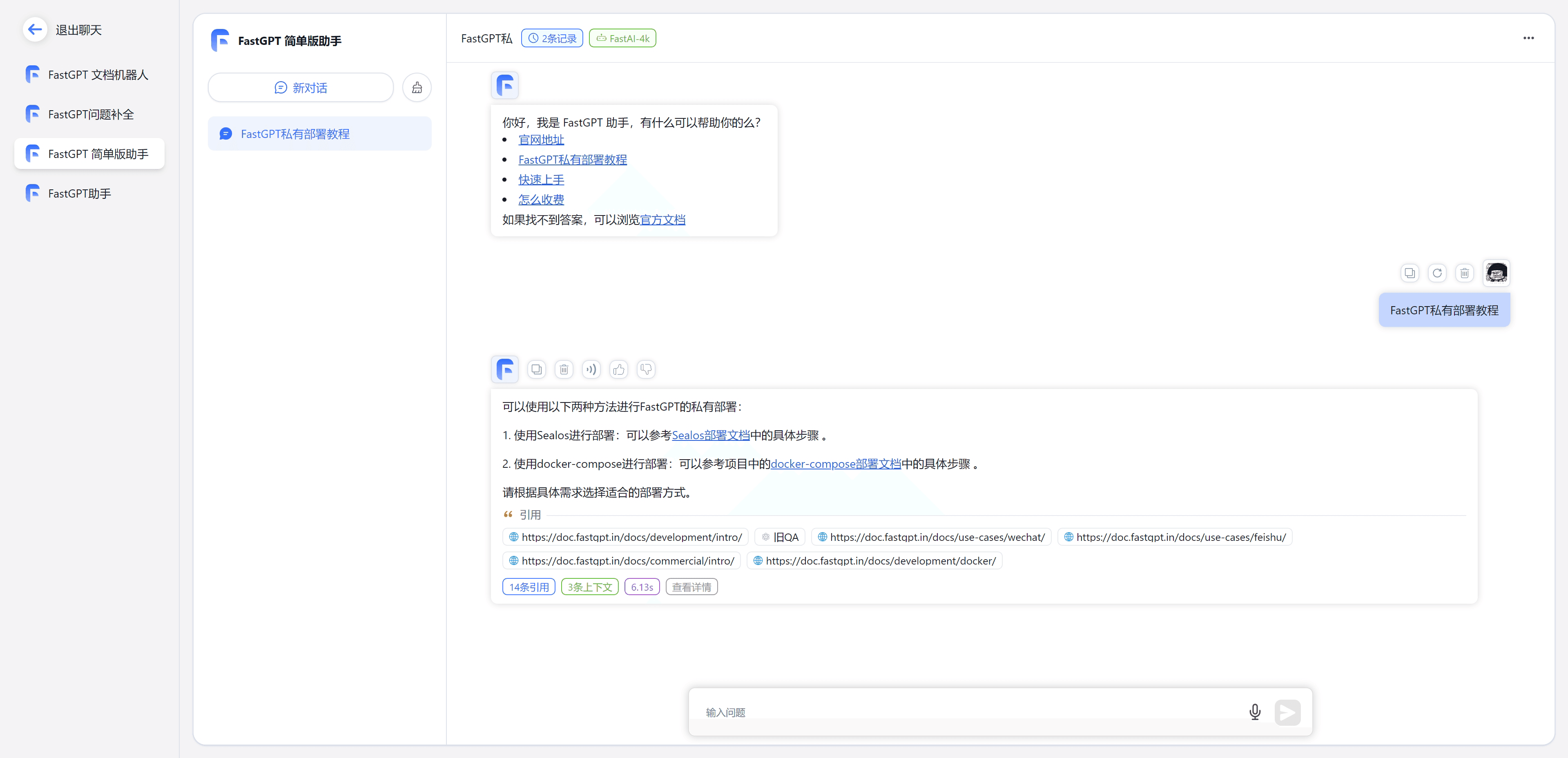 #### 4.RagFlow RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。 官网:https://ragflow.io/ Github:https://github.com/infiniflow/ragflow/blob/main ##### 4.1 功能介绍 * “Quality in, quality out” * 基于深度文档理解,能够从各类复杂格式的非结构化数据中提取真知灼见。 * 真正在无限上下文(token)的场景下快速完成大海捞针测试。 * 基于模板的文本切片 * 不仅仅是智能,更重要的是可控可解释。 * 多种文本模板可供选择 * 有理有据、最大程度降低幻觉(hallucination) * 文本切片过程可视化,支持手动调整。 * 有理有据:答案提供关键引用的快照并支持追根溯源。 * 兼容各类异构数据源 * 支持丰富的文件类型,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据、网页等。 * 全程无忧、自动化的 RAG 工作流 * 全面优化的 RAG 工作流可以支持从个人应用乃至超大型企业的各类生态系统。 * 大语言模型 LLM 以及向量模型均支持配置。 * 基于多路召回、融合重排序。 * 提供易用的 API,可以轻松集成到各类企业系统。 * 最近更新功能 * 2024-07-23 支持解析音频文件. * 2024-07-21 支持更多的大模型供应商(LocalAI/OpenRouter/StepFun/Nvidia). * 2024-07-18 在Graph中支持算子:Wikipedia,PubMed,Baidu和Duckduckgo. * 2024-07-08 支持 Agentic RAG: 基于 Graph 的工作流。 ##### 4.2 系统架构 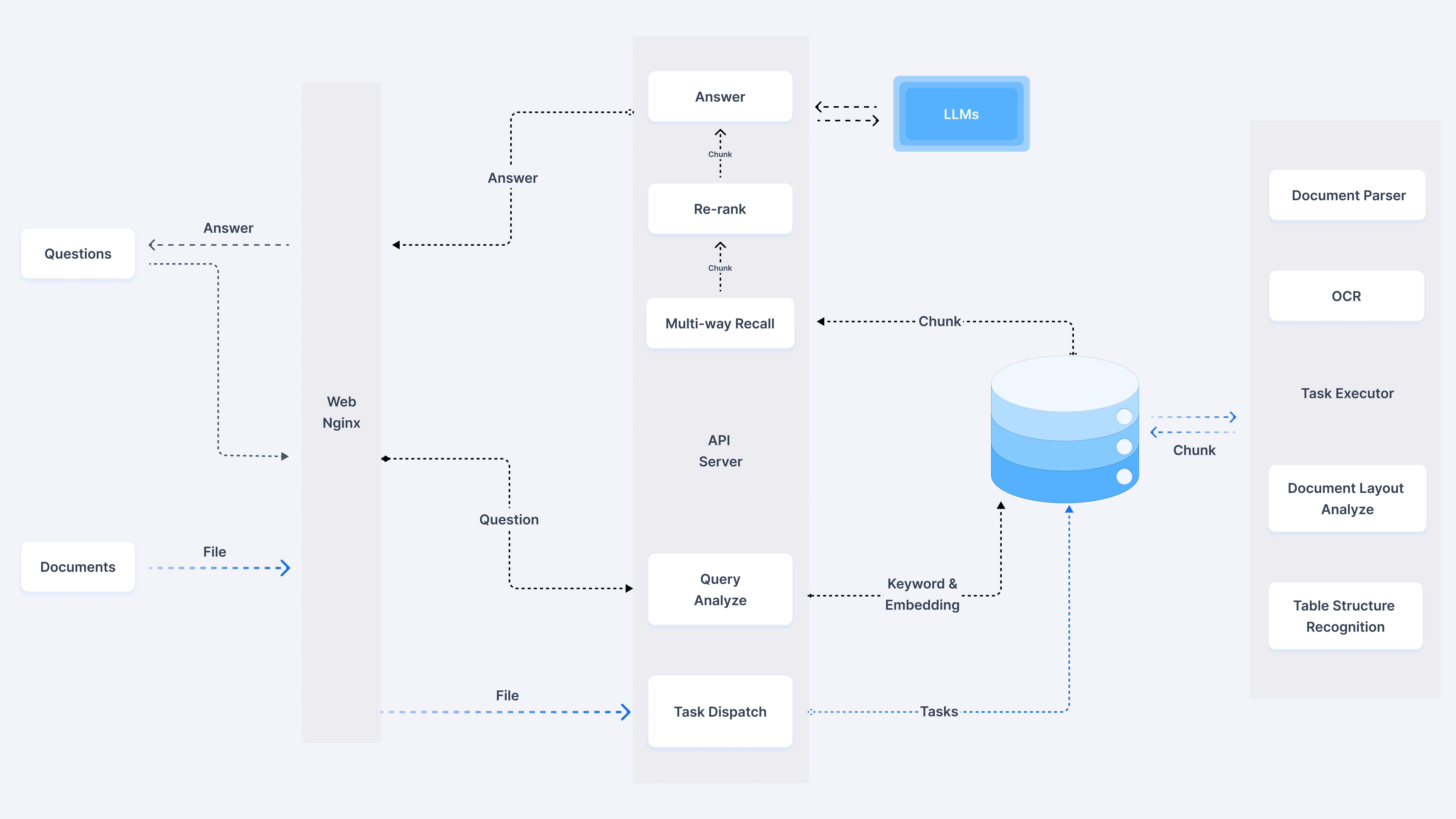 #### 5.Anything-LLM AnythingLLM是一个全栈应用程序,您可以使用现成的商业大语言模型或流行的开源大语言模型,再结合向量数据库解决方案构建一个私有ChatGPT,不再受制于人:您可以本地运行,也可以远程托管,并能够与您提供的任何文档智能聊天。 AnythingLLM将您的文档划分为称为workspaces (工作区)的对象。工作区的功能类似于线程,同时增加了文档的容器化,。工作区可以共享文档,但工作区之间的内容不会互相干扰或污染,因此您可以保持每个工作区的上下文清晰。 官方:https://anythingllm.com/ github:https://github.com/Mintplex-Labs/anything-llm 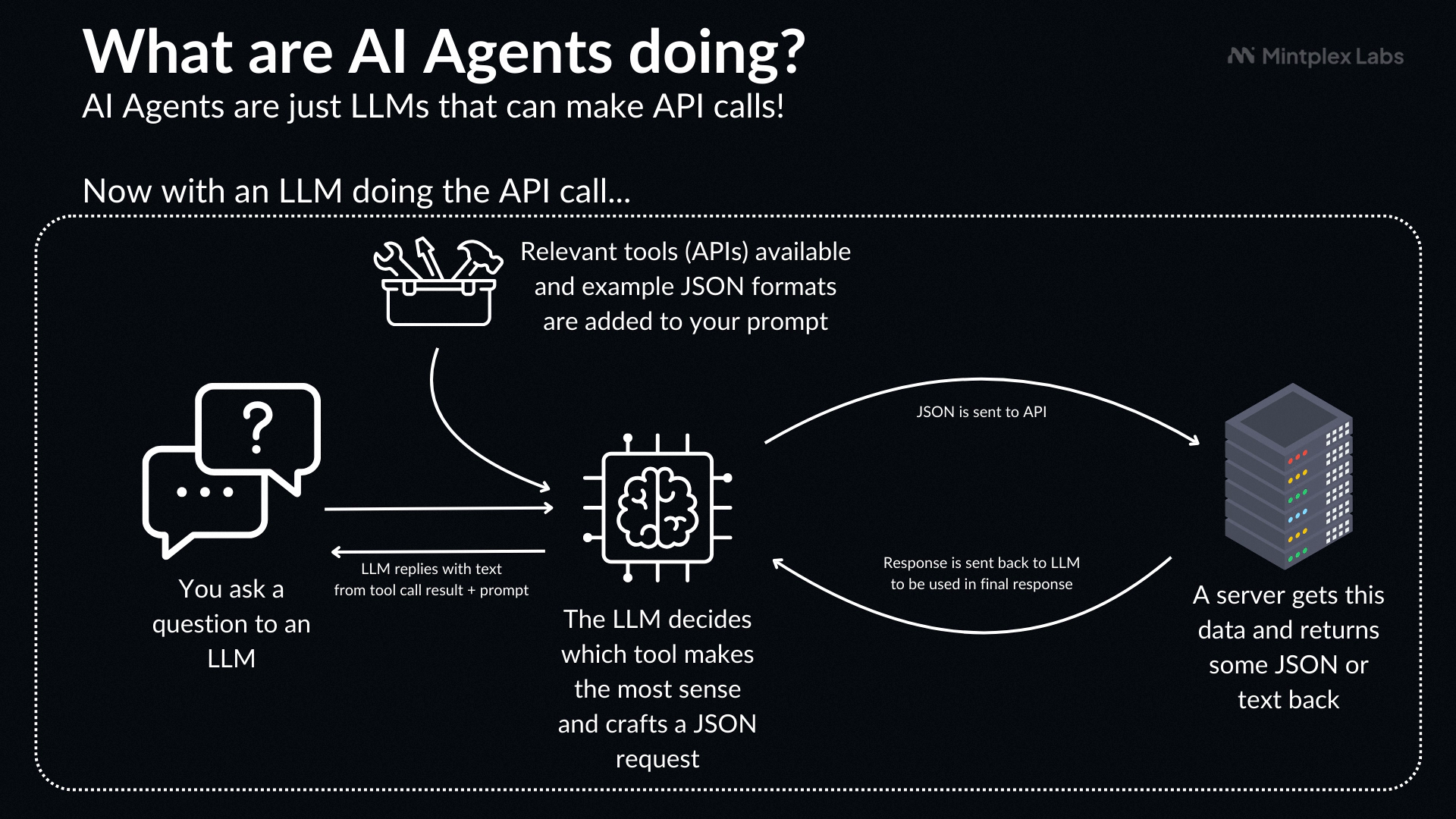 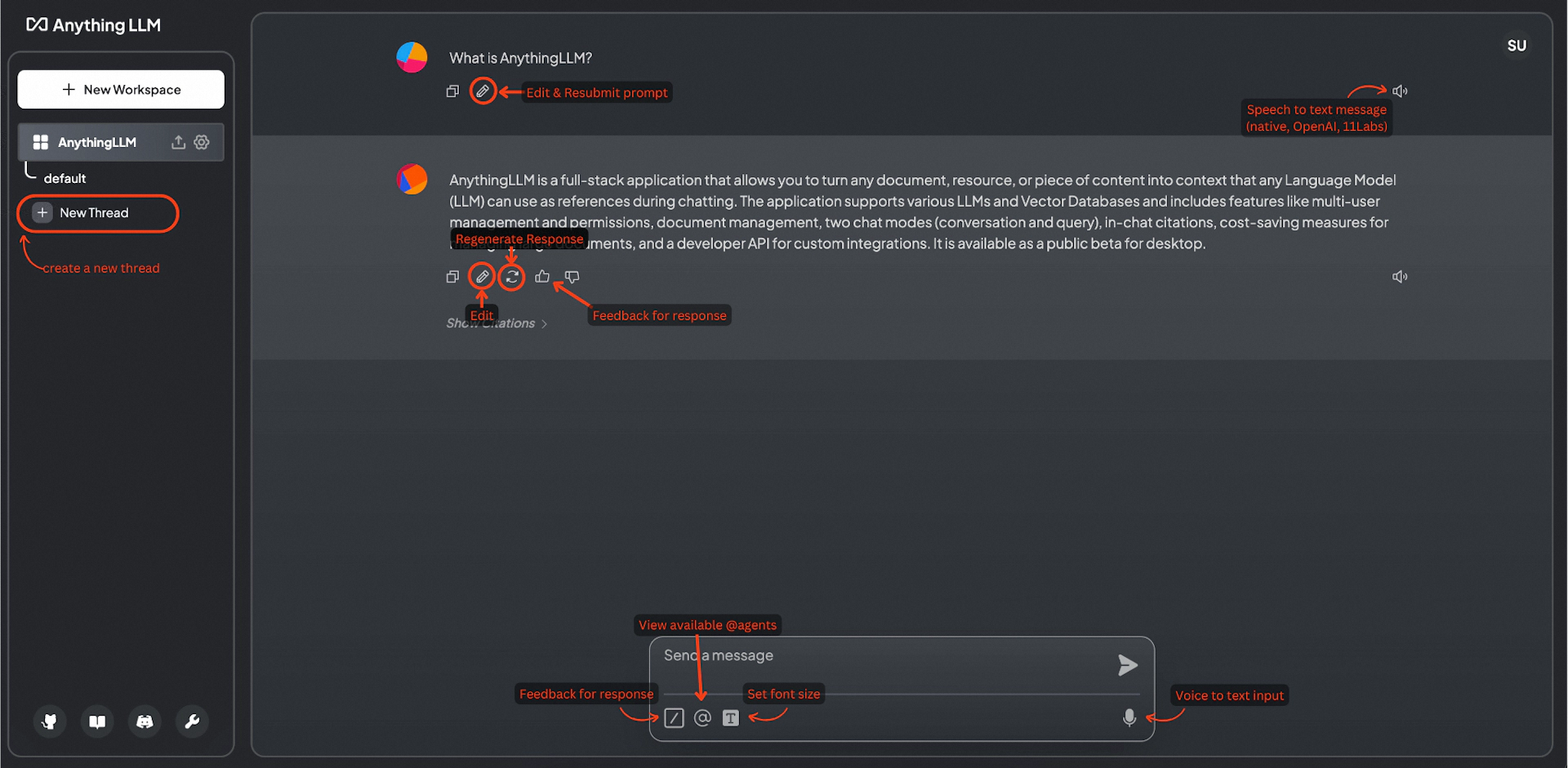 * AnythingLLM的一些特性 * 多用户实例支持和权限管理 * 工作区内的智能体Agent(浏览网页、运行代码等) * 为您的网站定制的可嵌入聊天窗口 * 支持多种文档类型(PDF、TXT、DOCX等) * 通过简单的用户界面管理向量数据库中的文档 * 两种对话模式:聊天和查询。聊天模式保留先前的对话记录。查询模式则是是针对您的文档做简单问答 * 聊天中会提供所引用的相应文档内容 * 100%云部署就绪。 * “部署你自己的LLM模型”。 * 管理超大文档时高效、低耗。只需要一次就可以嵌入(Embedding)一个庞大的文档或文字记录。比其他文档聊天机器人解决方案节省90%的成本。 * 全套的开发人员API,用于自定义集成! * 支持的 LLM、嵌入模型和向量数据库 * LLM:包括任何开源的 llama.cpp 兼容模型、OpenAI、Azure OpenAI、Anthropic ClaudeV2、LM Studio 和 LocalAi。 * 嵌入模型:AnythingLLM 原生嵌入器、OpenAI、Azure OpenAI、LM Studio 和 LocalAi。 * 向量数据库:LanceDB(默认)、Pinecone、Chroma、Weaviate 和 QDrant。 * 技术概览 * 整个项目设计为单线程结构,主要由三部分组成:收集器、前端和服务器。 * collector:Python 工具,可快速将在线资源或本地文档转换为 LLM 可用格式。 * frontend:ViteJS + React 前端,用于创建和管理 LLM 可使用的所有内容。 * server:NodeJS + Express 服务器,处理所有向量数据库管理和 LLM 交互。  #### 6.更多LLM框架推荐  **更多框架推荐参考下述文章:LLM框架、RAG框架、Agent框架** * [LLMops如何重塑AI-native新范式的运维格局[行业范式]、以及主流LLMops推荐](https://cloud.tencent.com/developer/tools/blog-entry?target=https%3A%2F%2Fblog.csdn.net%2Fsinat_39620217%2Farticle%2Fdetails%2F140550807&source=article&objectId=2441799) * [国内大模型+Agent应用案例精选,以及主流Agent框架开源项目推荐](https://cloud.tencent.com/developer/tools/blog-entry?target=https%3A%2F%2Fblog.csdn.net%2Fsinat_39620217%2Farticle%2Fdetails%2F140668919&source=article&objectId=2441799) ##### 6.1 DB-GPT: 用私有化LLM技术定义数据库下一代交互方式 DB-GPT是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。 目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。 > 数据3.0 时代,基于模型、数据库,企业/开发者可以用更少的代码搭建自己的专属应用。 * github:https://github.com/eosphoros-ai/DB-GPT 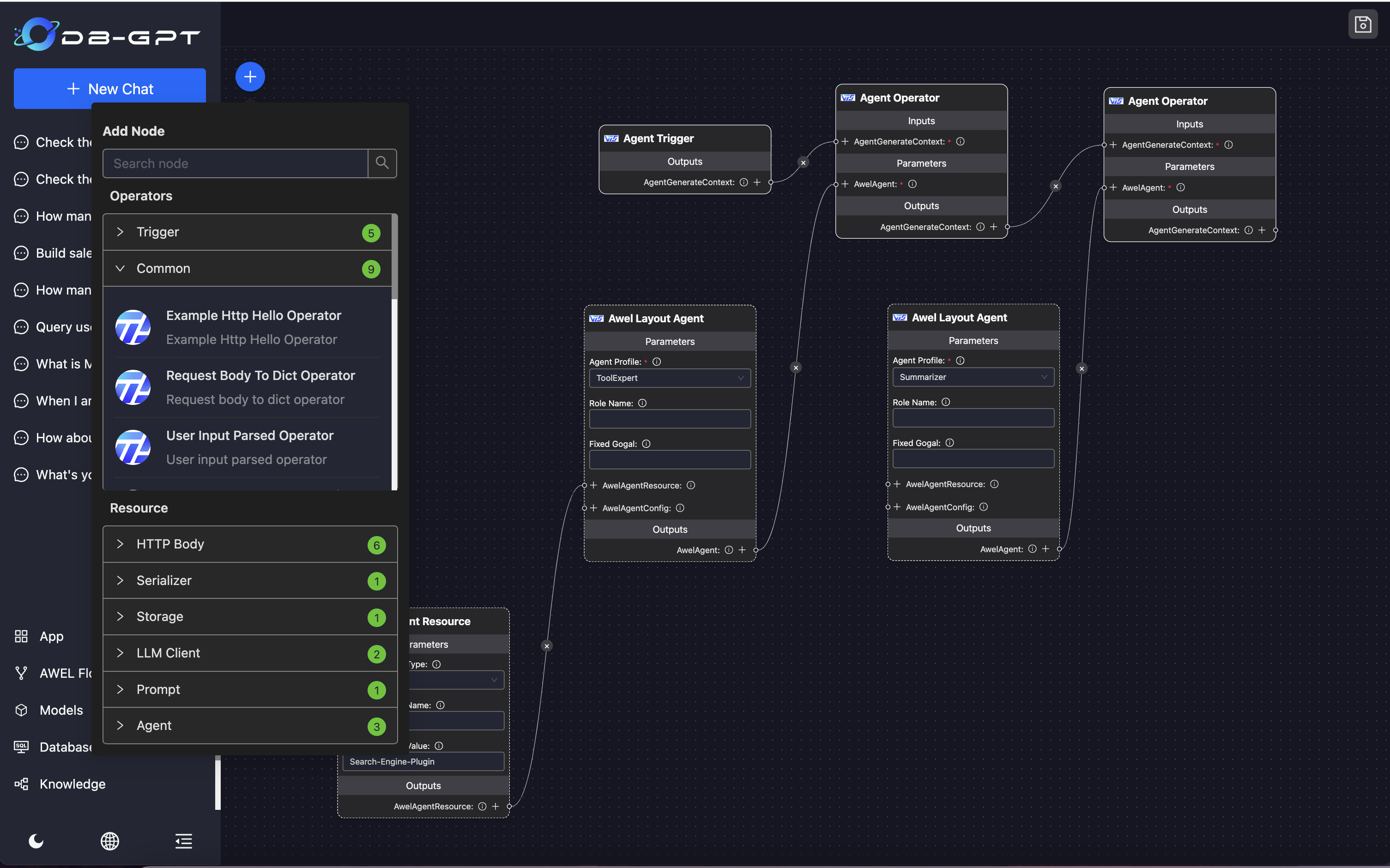 ###### 6.1.1 架构方案 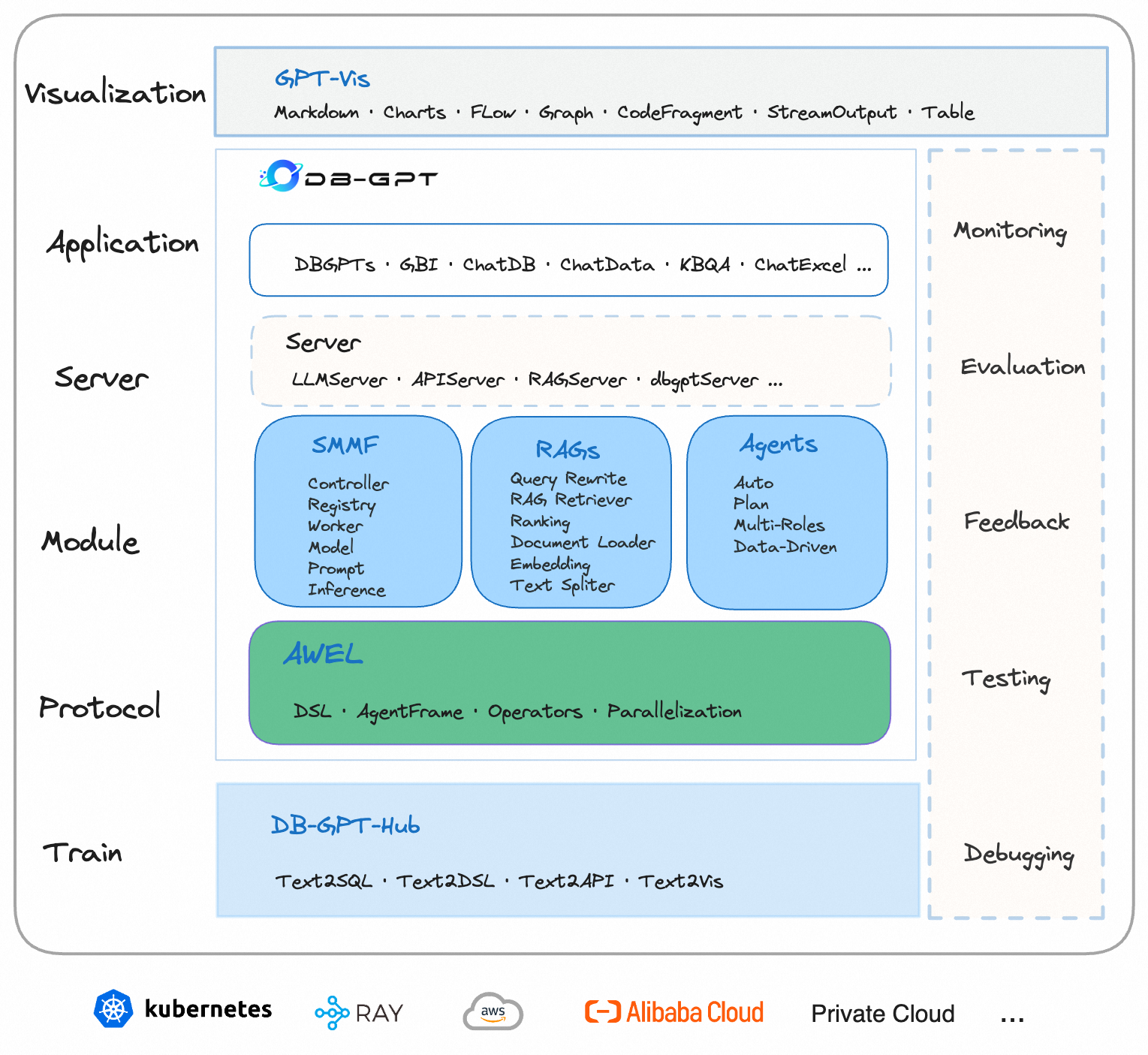 * 核心能力主要有以下几个部分: * RAG(Retrieval Augmented Generation),RAG是当下落地实践最多,也是最迫切的领域,DB-GPT目前已经实现了一套基于RAG的框架,用户可以基于DB-GPT的RAG能力构建知识类应用。 * GBI:生成式BI是DB-GPT项目的核心能力之一,为构建企业报表分析、业务洞察提供基础的数智化技术保障。 * 微调框架: 模型微调是任何一个企业在垂直、细分领域落地不可或缺的能力,DB-GPT提供了完整的微调框架,实现与DB-GPT项目的无缝打通,在最近的微调中,基于spider的准确率已经做到了82.5% * 数据驱动的Multi-Agents框架: DB-GPT提供了数据驱动的自进化Multi-Agents框架,目标是可以持续基于数据做决策与执行。 * 数据工厂: 数据工厂主要是在大模型时代,做可信知识、数据的清洗加工。 * 数据源: 对接各类数据源,实现生产业务数据无缝对接到DB-GPT核心能力。 ###### 6.1.2 RAG生产落地实践架构 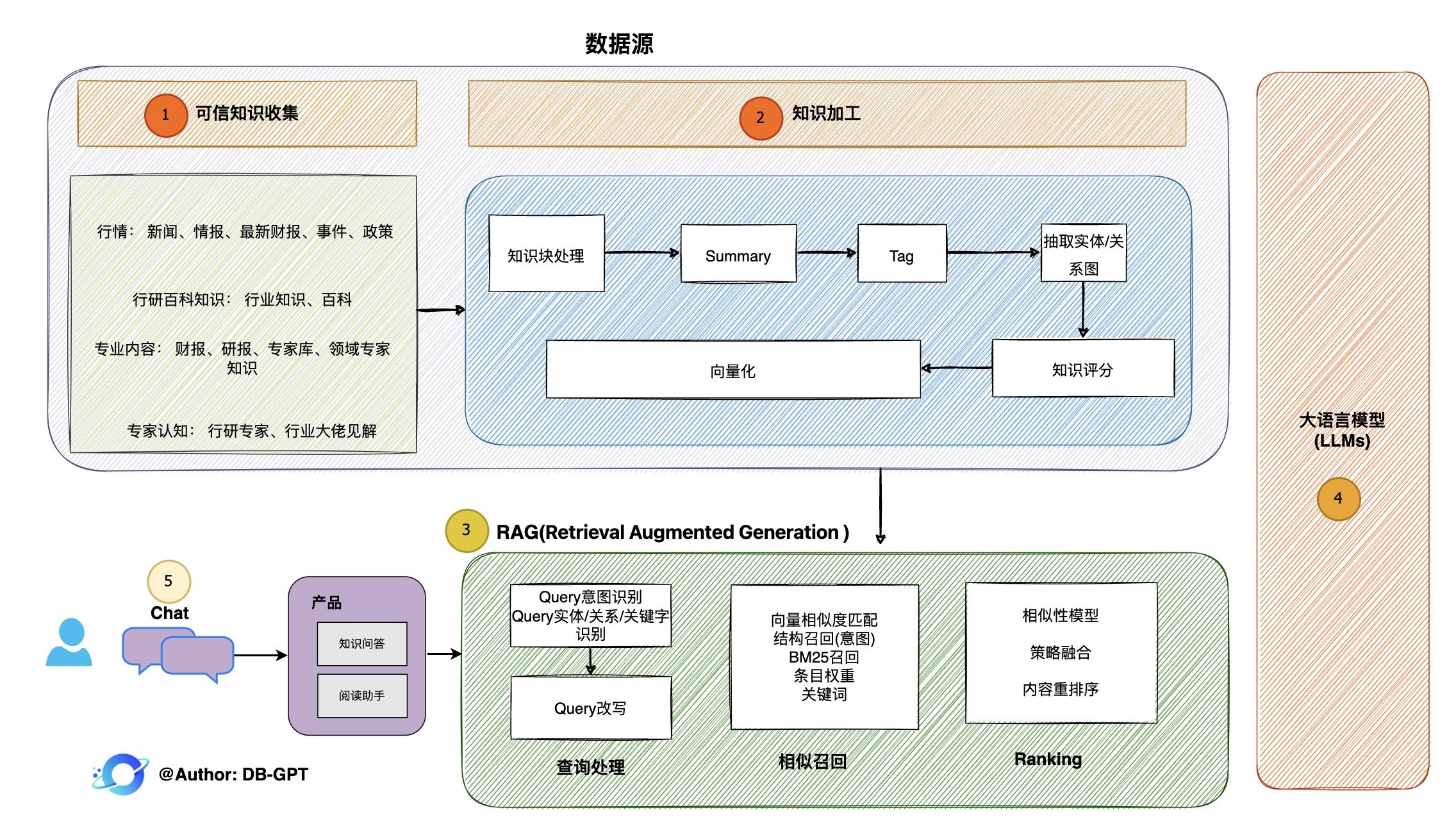 ##### 6.2 Langchain-Chatchat  * github:https://github.com/chatchat-space/Langchain-Chatchat 项目支持市面上主流的开源 LLM、 Embedding 模型与向量数据库,可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。 原理如下图所示:过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。 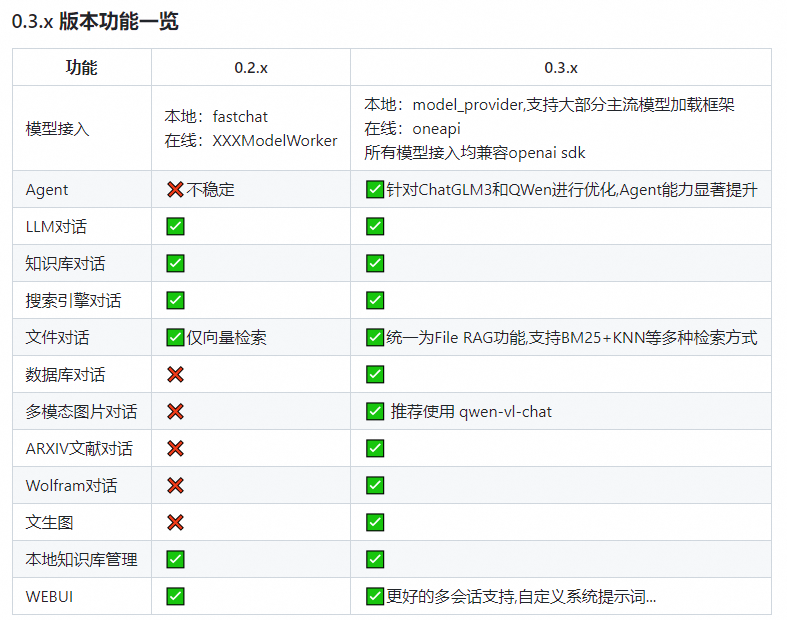 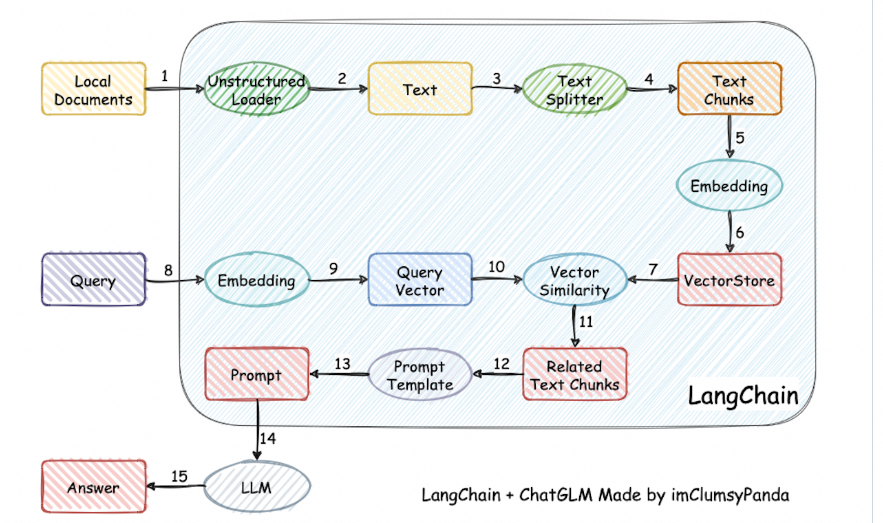 #### 7. 总结(选择建议) 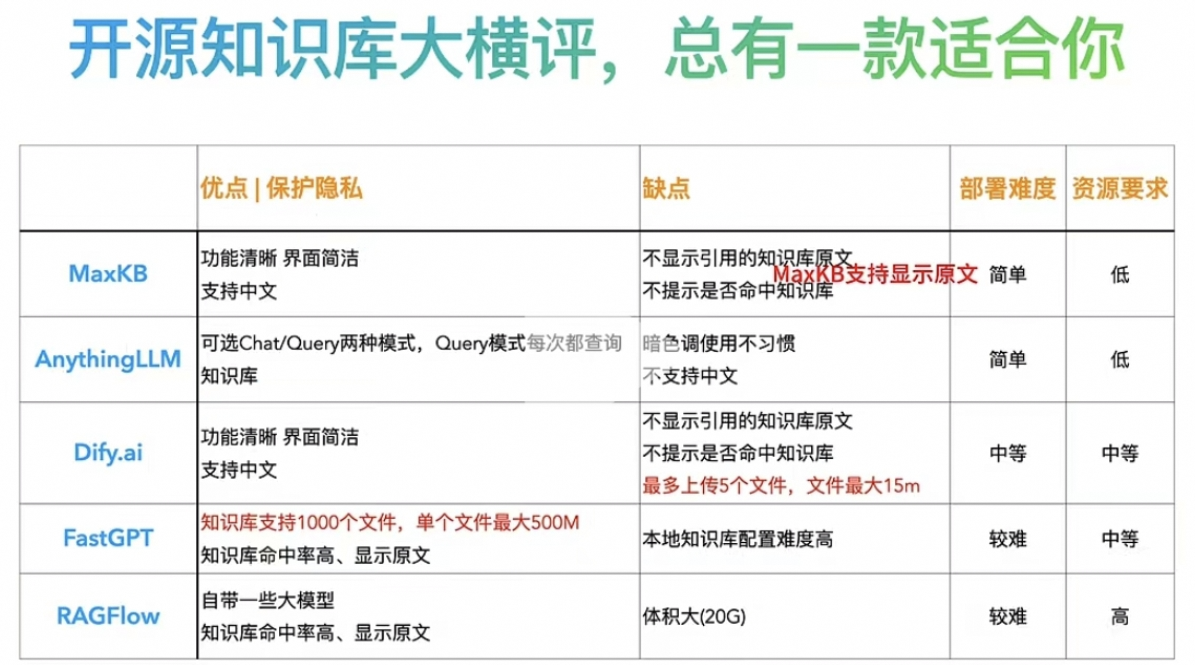 在选择AI应用开发平台时,了解不同平台的功能、社区支持以及部署便捷性是非常重要的。 ##### 7.0 优劣势选择 ###### MaxKB/Dify的优势与劣势 * **优势** * `大模型接入灵活性`:提供了多种大模型接入方式,支持多种API接口,使得开发者可以根据需求灵活选择和切换模型,这对于需要高性能模型的应用场景尤为重要。 * `强大的Chat功能`:Chat功能不仅支持多轮对话,还能通过智能推荐和上下文理解提升用户体验,适用于需要复杂交互的场景。 * `丰富的知识库支持`:内置了知识库管理系统,支持多种数据格式的导入和导出,便于用户管理和利用知识资源。 * `高效的Workflow设计`:Workflow设计简洁直观,支持拖拽式操作,使得非技术人员也能快速上手,大大降低了使用门槛。 * `Prompt IDE`:提供的Prompt IDE工具,让开发者可以更直观地调试和优化提示词,提升了开发效率。 * **劣势** * `学习曲线`:虽然界面设计较为友好,但对于初学者来说,仍需要一定时间来熟悉其工作流程和功能。 * `社区支持`:相较于一些成熟的开发平台,社区活跃度和资源丰富度还有待提升,这可能会影响到开发者在遇到问题时的解决速度。 * `定制化程度`:虽然Dify提供了丰富的功能,但在某些高度定制化的需求上,可能还需要进一步的开发和调整。 ###### FastGPT/RagFlow的优势与劣势 * 优势 * `Agent智能体`:Agent智能体功能强大,能够自动执行复杂任务,减少了人工干预的需求,适用于需要自动化处理大量任务的场景。 * `LLMOps支持`:提供了LLMOps支持,使得开发者可以更方便地进行模型训练、优化和部署,这对于AI模型的持续迭代和优化至关重要。 * `后端即服务`:提供了后端即服务的功能,简化了后端开发流程,使得开发者可以更专注于前端和业务逻辑的开发。 * `强大的RAG引擎`:RAG引擎能够高效地处理和检索大量数据,适用于需要快速响应和高吞吐量的应用场景。 * 劣势 * `功能复杂性`:FastGPT的功能较为复杂,对于初学者来说,可能需要较长时间来掌握其使用方法和技巧。 * `部署难度`:相较于一些轻量级的开发平台,FastGPT的部署过程可能更为复杂,需要一定的技术背景和经验。 * `用户界面`:虽然FastGPT的功能强大,但其用户界面可能不如一些竞争对手直观和友好,这可能会影响到用户的使用体验。 ##### 7.1 根据需求选择平台 选择合适的平台首先要明确自己的需求。Dify和FastGPT各有特点,适用于不同的应用场景。 * MaxKB/Dify:适合需要快速构建和部署AI应用的开发者,提供了丰富的预设模板和集成工具,使得开发者可以快速上手,尤其适合初学者和需要快速验证想法的团队。 * FastGPT/RagFlow:适合需要高度定制化和复杂工作流的企业级用户,提供了强大的RAG引擎和Workflow orchestration,能够处理复杂的业务逻辑和数据处理需求。 * 在选择平台时,应考虑以下因素: * 项目规模:如果是小型项目或初创团队,MaxKB/Dify的快速部署和简单易用性可能更适合。如果是大型企业级项目,FastGPT/RagFlow的强大功能和定制化能力更为合适。 * 技术栈:考虑团队现有的技术栈和成员的技术背景。在技术实现上有所不同,选择与团队技术栈匹配的平台可以减少学习成本和开发难度。 * 功能需求:明确项目所需的核心功能,如大模型接入、Chat功能、知识库等。Dify和FastGPT在这些功能上各有优势,根据具体需求进行选择。 ##### 7.2 社区与支持对比 社区支持和资源丰富度对于平台的选择也至关重要。 * MaxKB/Dify:拥有一个活跃的社区,提供了丰富的文档、教程和示例代码。社区成员经常分享使用心得和解决方案,对于遇到的问题可以快速得到帮助。 * FastGPT/RagFlow:社区相对较小,但提供了专业的技术支持团队。对于企业级用户,FastGPT提供了定制化的技术支持和咨询服务,确保项目的顺利进行。 * 在选择平台时,应考虑以下因素: * 社区活跃度:活跃的社区意味着更多的资源和更快的解决问题速度。社区活跃度较高,适合需要快速解决问题的开发者。 * 技术支持:对于企业级用户,专业的技术支持至关重要。提供了专业的技术支持,适合对技术支持有较高要求的用户。 ##### 7.3 部署与使用便捷性 部署和使用的便捷性直接影响开发效率和成本。 * MaxKB/Dify:提供了简单易用的界面和一键部署功能,使得开发者可以快速将应用部署到云端或本地。文档详细,适合初学者快速上手。 * FastGPT/RagFlow:部署相对复杂,需要一定的技术背景和配置。提供了强大的定制化能力,适合对性能和功能有较高要求的用户。 * 在选择平台时,应考虑以下因素: * 部署难度:MaxKB/Dify的部署过程简单,适合需要快速部署的开发者。FastGPT/RagFlow的部署相对复杂,但提供了更多的配置选项。 * 使用便捷性:MaxKB/Dify的用户界面友好,操作简单。FastGPT/RagFlow的用户界面相对复杂,但提供了更多的功能和定制化选项。 ## 程序员为什么要学大模型? 大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “`AI会取代那些行业`?”“`谁的饭碗又将不保了?`”等问题热议不断。 事实上,**`抢你饭碗的不是AI,而是会利用AI的人。`** 继`科大讯飞、阿里、华为`等巨头公司发布AI产品后,很多中小企业也陆续进场!**超高年薪,挖掘AI大模型人才!** 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗? ###### 与其焦虑…… 不如成为「`掌握AI工具的技术人`」,毕竟AI时代,**谁先尝试,谁就能占得先机!** **但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。** Loading...  #### 1.MaxKB MaxKB = Max Knowledge Base,是一款基于 LLM 大语言模型的开源[知识库](https://so.csdn.net/so/search?q=%E7%9F%A5%E8%AF%86%E5%BA%93&spm=1001.2101.3001.7020)问答系统,旨在成为企业的最强大脑。它能够帮助企业高效地管理知识,并提供智能问答功能。想象一下,你有一个虚拟助手,可以回答各种关于公司内部知识的问题,无论是政策、流程,还是技术文档,MaxKB 都能快速准确地给出答案:比如公司内网如何访问、如何提交视觉设计需求等等 官方网址:https://maxkb.cn/ ##### 1.1 简介 1. `开箱即用`:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化、RAG(检索增强生成),智能问答交互体验好; 2. `无缝嵌入`:支持零编码快速嵌入到第三方业务系统,让已有系统快速拥有智能问答能力,提高用户满意度;  1. `灵活编排`:内置强大的工作流引擎,支持编排 AI 工作流程,满足复杂业务场景下的需求; 2. `模型中立`:支持对接各种大语言模型,包括本地私有大模型(Llama 3 / Qwen 2 等)、国内公共大模型(通义千问 / 智谱 AI / 百度千帆 / Kimi / DeepSeek 等)和国外公共大模型(OpenAI / Azure OpenAI / Gemini 等)。  ##### 技术框架和原理   * 技术栈 * 前端:Vue.js、logicflow * 后端:Python / Django * Langchain:Langchain * 向量数据库:PostgreSQL / pgvector * 大模型:Ollama、Azure OpenAI、OpenAI、通义千问、Kimi、百度千帆大模型、讯飞星火、Gemini、DeepSeek等。 #### 2.Dify Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。 由于 Dify 内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的流程编排,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上  * 官网:https://dify.ai/zh * github:https://github.com/langgenius/dify?tab=readme-ov-file ##### 2.1 简介 Dify 是一个开源的 LLM 应用开发平台。其直观的界面结合了 AI 工作流、RAG 管道、Agent、模型管理、可观测性功能等,让您可以快速从原型到生产。以下是其核心功能列表: 1. `工作流`: 在画布上构建和测试功能强大的 AI 工作流程,利用以下所有功能以及更多功能。 2. `全面的模型支持`: 与数百种专有/开源 LLMs 以及数十种推理提供商和自托管解决方案无缝集成,涵盖 GPT、Mistral、Llama3 以及任何与 OpenAI API 兼容的模型。 3. `Prompt IDE`: 用于制作提示、比较模型性能以及向基于聊天的应用程序添加其他功能(如文本转语音)的直观界面。 4. `RAG Pipeline`: 广泛的 RAG 功能,涵盖从文档摄入到检索的所有内容,支持从 PDF、PPT 和其他常见文档格式中提取文本的开箱即用的支持。 5. `Agent 智能体`: 您可以基于 LLM 函数调用或 ReAct 定义 Agent,并为 Agent 添加预构建或自定义工具。Dify 为 AI Agent 提供了50多种内置工具,如谷歌搜索、DELL·E、Stable Diffusion 和 WolframAlpha 等。 6. `LLMOps`: 随时间监视和分析应用程序日志和性能。您可以根据生产数据和标注持续改进提示、数据集和模型。 7. `后端即服务`: 所有 Dify 的功能都带有相应的 API,因此您可以轻松地将 Dify 集成到自己的业务逻辑中。 ##### 2.2 系统框架  工作流通过将复杂的任务分解成较小的步骤(节点)降低系统复杂度,减少了对提示词技术和模型推理能力的依赖,提高了 LLM 应用面向复杂任务的性能,提升了系统的可解释性、稳定性和容错性。 Dify 工作流分为两种类型: * Chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。 * Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。 为解决自然语言输入中用户意图识别的复杂性,Chatflow 提供了问题理解类节点。相对于 Workflow 增加了 Chatbot 特性的支持,如:对话历史(Memory)、标注回复、Answer 节点等。 为解决自动化和批处理情景中复杂业务逻辑,工作流提供了丰富的逻辑节点,如代码节点、IF/ELSE 节点、模板转换、迭代节点等,除此之外也将提供定时和事件触发的能力,方便构建自动化流程。 * 常见案例 * 客户服务:通过将 LLM 集成到您的客户服务系统中,您可以自动化回答常见问题,减轻支持团队的工作负担。 LLM 可以理解客户查询的上下文和意图,并实时生成有帮助且准确的回答。 * 内容生成:无论您需要创建博客文章、产品描述还是营销材料,LLM 都可以通过生成高质量内容来帮助您。只需提供一个大纲或主题,LLM将利用其广泛的知识库来制作引人入胜、信息丰富且结构良好的内容。 * 任务自动化:可以与各种任务管理系统集成,如 Trello、Slack、Lark、以自动化项目和任务管理。通过使用自然语言处理,LLM 可以理解和解释用户输入,创建任务,更新状态和分配优先级,无需手动干预。 * 数据分析和报告:可以用于分析大型数据集并生成报告或摘要。通过提供相关信息给 LLM,它可以识别趋势、模式和洞察力,将原始数据转化为可操作的智能。对于希望做出数据驱动决策的企业来说,这尤其有价值。 * 邮件自动化处理:LLM 可以用于起草电子邮件、社交媒体更新和其他形式的沟通。通过提供简要的大纲或关键要点,LLM 可以生成一个结构良好、连贯且与上下文相关的信息。这样可以节省大量时间,并确保您的回复清晰和专业。 #### 3.FastGPT FastGPT是一个功能强大的平台,专注于知识库训练和自动化工作流程的编排。它提供了一个简单易用的可视化界面,支持自动数据预处理和基于Flow模块的工作流编排。FastGPT支持创建RAG系统,提供自动化工作流程等功能,使得构建和使用RAG系统变得简单,无需编写复杂代码。 * 官方:https://fastgpt.in/ * github:https://github.com/labring/FastGPT ##### 3.1 FastGPT 能力 1. `专属 AI 客服` :通过导入文档或已有问答对进行训练,让 AI 模型能根据你的文档以交互式对话方式回答问题。 * 多库复用,混用 * chunk 记录修改和删除 * 源文件存储 * 支持手动输入,直接分段,QA 拆分导入 * 支持 txt,md,html,pdf,docx,pptx,csv,xlsx (有需要更多可 PR file loader) * 支持 url 读取、CSV 批量导入 * 混合检索 & 重排 2. `简单易用的可视化界面` :FastGPT 采用直观的可视化界面设计,为各种应用场景提供了丰富实用的功能。通过简洁易懂的操作步骤,可以轻松完成 AI 客服的创建和训练流程。 3. `自动数据预处理`:提供手动输入、直接分段、LLM 自动处理和 CSV 等多种数据导入途径,其中“直接分段”支持通过 PDF、WORD、Markdown 和 CSV 文档内容作为上下文。FastGPT 会自动对文本数据进行预处理、向量化和 QA 分割,节省手动训练时间,提升效能。 4. `工作流编排` :基于 Flow 模块的工作流编排,可以帮助你设计更加复杂的问答流程。例如查询数据库、查询库存、预约实验室等。 * 提供简易模式,无需操作编排 * 工作流编排 * 工具调用 * 插件 - 工作流封装能力 * Code sandbox 5. `强大的 API 集成` :FastGPT 对外的 API 接口对齐了 OpenAI 官方接口,可以直接接入现有的 GPT 应用,也可以轻松集成到企业微信、公众号、飞书等平台。     #### 4.RagFlow RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。 官网:https://ragflow.io/ Github:https://github.com/infiniflow/ragflow/blob/main ##### 4.1 功能介绍 * “Quality in, quality out” * 基于深度文档理解,能够从各类复杂格式的非结构化数据中提取真知灼见。 * 真正在无限上下文(token)的场景下快速完成大海捞针测试。 * 基于模板的文本切片 * 不仅仅是智能,更重要的是可控可解释。 * 多种文本模板可供选择 * 有理有据、最大程度降低幻觉(hallucination) * 文本切片过程可视化,支持手动调整。 * 有理有据:答案提供关键引用的快照并支持追根溯源。 * 兼容各类异构数据源 * 支持丰富的文件类型,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据、网页等。 * 全程无忧、自动化的 RAG 工作流 * 全面优化的 RAG 工作流可以支持从个人应用乃至超大型企业的各类生态系统。 * 大语言模型 LLM 以及向量模型均支持配置。 * 基于多路召回、融合重排序。 * 提供易用的 API,可以轻松集成到各类企业系统。 * 最近更新功能 * 2024-07-23 支持解析音频文件. * 2024-07-21 支持更多的大模型供应商(LocalAI/OpenRouter/StepFun/Nvidia). * 2024-07-18 在Graph中支持算子:Wikipedia,PubMed,Baidu和Duckduckgo. * 2024-07-08 支持 Agentic RAG: 基于 Graph 的工作流。 ##### 4.2 系统架构  #### 5.Anything-LLM AnythingLLM是一个全栈应用程序,您可以使用现成的商业大语言模型或流行的开源大语言模型,再结合向量数据库解决方案构建一个私有ChatGPT,不再受制于人:您可以本地运行,也可以远程托管,并能够与您提供的任何文档智能聊天。 AnythingLLM将您的文档划分为称为workspaces (工作区)的对象。工作区的功能类似于线程,同时增加了文档的容器化,。工作区可以共享文档,但工作区之间的内容不会互相干扰或污染,因此您可以保持每个工作区的上下文清晰。 官方:https://anythingllm.com/ github:https://github.com/Mintplex-Labs/anything-llm   * AnythingLLM的一些特性 * 多用户实例支持和权限管理 * 工作区内的智能体Agent(浏览网页、运行代码等) * 为您的网站定制的可嵌入聊天窗口 * 支持多种文档类型(PDF、TXT、DOCX等) * 通过简单的用户界面管理向量数据库中的文档 * 两种对话模式:聊天和查询。聊天模式保留先前的对话记录。查询模式则是是针对您的文档做简单问答 * 聊天中会提供所引用的相应文档内容 * 100%云部署就绪。 * “部署你自己的LLM模型”。 * 管理超大文档时高效、低耗。只需要一次就可以嵌入(Embedding)一个庞大的文档或文字记录。比其他文档聊天机器人解决方案节省90%的成本。 * 全套的开发人员API,用于自定义集成! * 支持的 LLM、嵌入模型和向量数据库 * LLM:包括任何开源的 llama.cpp 兼容模型、OpenAI、Azure OpenAI、Anthropic ClaudeV2、LM Studio 和 LocalAi。 * 嵌入模型:AnythingLLM 原生嵌入器、OpenAI、Azure OpenAI、LM Studio 和 LocalAi。 * 向量数据库:LanceDB(默认)、Pinecone、Chroma、Weaviate 和 QDrant。 * 技术概览 * 整个项目设计为单线程结构,主要由三部分组成:收集器、前端和服务器。 * collector:Python 工具,可快速将在线资源或本地文档转换为 LLM 可用格式。 * frontend:ViteJS + React 前端,用于创建和管理 LLM 可使用的所有内容。 * server:NodeJS + Express 服务器,处理所有向量数据库管理和 LLM 交互。  #### 6.更多LLM框架推荐  **更多框架推荐参考下述文章:LLM框架、RAG框架、Agent框架** * [LLMops如何重塑AI-native新范式的运维格局[行业范式]、以及主流LLMops推荐](https://cloud.tencent.com/developer/tools/blog-entry?target=https%3A%2F%2Fblog.csdn.net%2Fsinat_39620217%2Farticle%2Fdetails%2F140550807&source=article&objectId=2441799) * [国内大模型+Agent应用案例精选,以及主流Agent框架开源项目推荐](https://cloud.tencent.com/developer/tools/blog-entry?target=https%3A%2F%2Fblog.csdn.net%2Fsinat_39620217%2Farticle%2Fdetails%2F140668919&source=article&objectId=2441799) ##### 6.1 DB-GPT: 用私有化LLM技术定义数据库下一代交互方式 DB-GPT是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。 目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。 > 数据3.0 时代,基于模型、数据库,企业/开发者可以用更少的代码搭建自己的专属应用。 * github:https://github.com/eosphoros-ai/DB-GPT  ###### 6.1.1 架构方案  * 核心能力主要有以下几个部分: * RAG(Retrieval Augmented Generation),RAG是当下落地实践最多,也是最迫切的领域,DB-GPT目前已经实现了一套基于RAG的框架,用户可以基于DB-GPT的RAG能力构建知识类应用。 * GBI:生成式BI是DB-GPT项目的核心能力之一,为构建企业报表分析、业务洞察提供基础的数智化技术保障。 * 微调框架: 模型微调是任何一个企业在垂直、细分领域落地不可或缺的能力,DB-GPT提供了完整的微调框架,实现与DB-GPT项目的无缝打通,在最近的微调中,基于spider的准确率已经做到了82.5% * 数据驱动的Multi-Agents框架: DB-GPT提供了数据驱动的自进化Multi-Agents框架,目标是可以持续基于数据做决策与执行。 * 数据工厂: 数据工厂主要是在大模型时代,做可信知识、数据的清洗加工。 * 数据源: 对接各类数据源,实现生产业务数据无缝对接到DB-GPT核心能力。 ###### 6.1.2 RAG生产落地实践架构  ##### 6.2 Langchain-Chatchat  * github:https://github.com/chatchat-space/Langchain-Chatchat 项目支持市面上主流的开源 LLM、 Embedding 模型与向量数据库,可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。 原理如下图所示:过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。   #### 7. 总结(选择建议)  在选择AI应用开发平台时,了解不同平台的功能、社区支持以及部署便捷性是非常重要的。 ##### 7.0 优劣势选择 ###### MaxKB/Dify的优势与劣势 * **优势** * `大模型接入灵活性`:提供了多种大模型接入方式,支持多种API接口,使得开发者可以根据需求灵活选择和切换模型,这对于需要高性能模型的应用场景尤为重要。 * `强大的Chat功能`:Chat功能不仅支持多轮对话,还能通过智能推荐和上下文理解提升用户体验,适用于需要复杂交互的场景。 * `丰富的知识库支持`:内置了知识库管理系统,支持多种数据格式的导入和导出,便于用户管理和利用知识资源。 * `高效的Workflow设计`:Workflow设计简洁直观,支持拖拽式操作,使得非技术人员也能快速上手,大大降低了使用门槛。 * `Prompt IDE`:提供的Prompt IDE工具,让开发者可以更直观地调试和优化提示词,提升了开发效率。 * **劣势** * `学习曲线`:虽然界面设计较为友好,但对于初学者来说,仍需要一定时间来熟悉其工作流程和功能。 * `社区支持`:相较于一些成熟的开发平台,社区活跃度和资源丰富度还有待提升,这可能会影响到开发者在遇到问题时的解决速度。 * `定制化程度`:虽然Dify提供了丰富的功能,但在某些高度定制化的需求上,可能还需要进一步的开发和调整。 ###### FastGPT/RagFlow的优势与劣势 * 优势 * `Agent智能体`:Agent智能体功能强大,能够自动执行复杂任务,减少了人工干预的需求,适用于需要自动化处理大量任务的场景。 * `LLMOps支持`:提供了LLMOps支持,使得开发者可以更方便地进行模型训练、优化和部署,这对于AI模型的持续迭代和优化至关重要。 * `后端即服务`:提供了后端即服务的功能,简化了后端开发流程,使得开发者可以更专注于前端和业务逻辑的开发。 * `强大的RAG引擎`:RAG引擎能够高效地处理和检索大量数据,适用于需要快速响应和高吞吐量的应用场景。 * 劣势 * `功能复杂性`:FastGPT的功能较为复杂,对于初学者来说,可能需要较长时间来掌握其使用方法和技巧。 * `部署难度`:相较于一些轻量级的开发平台,FastGPT的部署过程可能更为复杂,需要一定的技术背景和经验。 * `用户界面`:虽然FastGPT的功能强大,但其用户界面可能不如一些竞争对手直观和友好,这可能会影响到用户的使用体验。 ##### 7.1 根据需求选择平台 选择合适的平台首先要明确自己的需求。Dify和FastGPT各有特点,适用于不同的应用场景。 * MaxKB/Dify:适合需要快速构建和部署AI应用的开发者,提供了丰富的预设模板和集成工具,使得开发者可以快速上手,尤其适合初学者和需要快速验证想法的团队。 * FastGPT/RagFlow:适合需要高度定制化和复杂工作流的企业级用户,提供了强大的RAG引擎和Workflow orchestration,能够处理复杂的业务逻辑和数据处理需求。 * 在选择平台时,应考虑以下因素: * 项目规模:如果是小型项目或初创团队,MaxKB/Dify的快速部署和简单易用性可能更适合。如果是大型企业级项目,FastGPT/RagFlow的强大功能和定制化能力更为合适。 * 技术栈:考虑团队现有的技术栈和成员的技术背景。在技术实现上有所不同,选择与团队技术栈匹配的平台可以减少学习成本和开发难度。 * 功能需求:明确项目所需的核心功能,如大模型接入、Chat功能、知识库等。Dify和FastGPT在这些功能上各有优势,根据具体需求进行选择。 ##### 7.2 社区与支持对比 社区支持和资源丰富度对于平台的选择也至关重要。 * MaxKB/Dify:拥有一个活跃的社区,提供了丰富的文档、教程和示例代码。社区成员经常分享使用心得和解决方案,对于遇到的问题可以快速得到帮助。 * FastGPT/RagFlow:社区相对较小,但提供了专业的技术支持团队。对于企业级用户,FastGPT提供了定制化的技术支持和咨询服务,确保项目的顺利进行。 * 在选择平台时,应考虑以下因素: * 社区活跃度:活跃的社区意味着更多的资源和更快的解决问题速度。社区活跃度较高,适合需要快速解决问题的开发者。 * 技术支持:对于企业级用户,专业的技术支持至关重要。提供了专业的技术支持,适合对技术支持有较高要求的用户。 ##### 7.3 部署与使用便捷性 部署和使用的便捷性直接影响开发效率和成本。 * MaxKB/Dify:提供了简单易用的界面和一键部署功能,使得开发者可以快速将应用部署到云端或本地。文档详细,适合初学者快速上手。 * FastGPT/RagFlow:部署相对复杂,需要一定的技术背景和配置。提供了强大的定制化能力,适合对性能和功能有较高要求的用户。 * 在选择平台时,应考虑以下因素: * 部署难度:MaxKB/Dify的部署过程简单,适合需要快速部署的开发者。FastGPT/RagFlow的部署相对复杂,但提供了更多的配置选项。 * 使用便捷性:MaxKB/Dify的用户界面友好,操作简单。FastGPT/RagFlow的用户界面相对复杂,但提供了更多的功能和定制化选项。 ## 程序员为什么要学大模型? 大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “`AI会取代那些行业`?”“`谁的饭碗又将不保了?`”等问题热议不断。 事实上,**`抢你饭碗的不是AI,而是会利用AI的人。`** 继`科大讯飞、阿里、华为`等巨头公司发布AI产品后,很多中小企业也陆续进场!**超高年薪,挖掘AI大模型人才!** 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗? ###### 与其焦虑…… 不如成为「`掌握AI工具的技术人`」,毕竟AI时代,**谁先尝试,谁就能占得先机!** **但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。** 最后修改:2025 年 04 月 16 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
